Introduction
Following the breakthrough in GenAI with ChatGPT, a plethora of foundational LLMs, including both closed and open models, have emerged. Hugging Face boasts an extensive array of open LLMs. Amid the abundance of closed and open LLM options, various other techniques have surfaced, making it challenging to determine the right path and option. These techniques can lead to confusion when deciding whether to use closed LLM models as-is (via APIs), self-host open LLM models, set up quantized models, or fine-tune models. The ultimate choice of approach depends on the accuracy required for a given use case. However, this blog post aims to provide a structured framework for a progressive journey towards developing solutions or building internal organizational capabilities. This progression starts from simple approaches and gradually moves toward more complex ones.
We have divided this blog into a two-part series: LLM experiments without fine-tuning and with fine-tuning. In this blog, we will concentrate on the progressive journey of LLM experiments without involving any fine-tuning. Please note that this blog focuses on embarking on a progressive journey through various approaches and options for using and hosting LLMs rather than selecting the right LLM.
Prompting Progression Strategy
Prompting techniques are widely known as an effective way to elicit creative and concise responses from LLMs. Prompt engineering has also evolved, and here, we present a commonly discussed progression strategy from an experimentation perspective to achieve better and more accurate results.
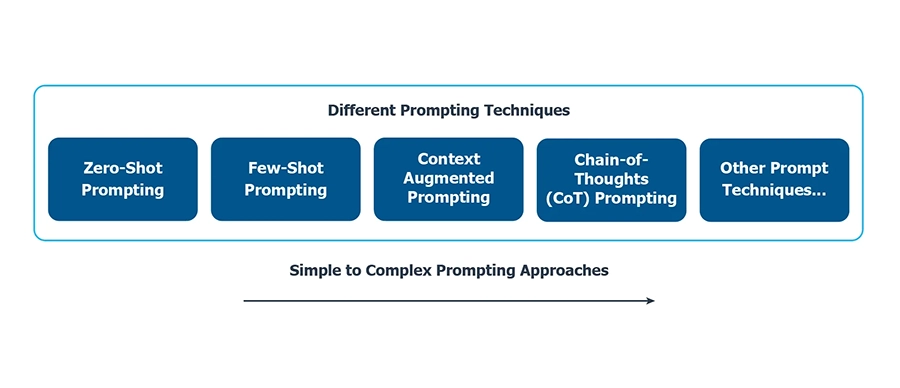
You can find more prompting techniques here.
Progressive Journey for LLM Experiments
Just as there is a progression strategy for prompting to improve results, there are various techniques for using, experimenting with, and hosting LLMs. The following diagram outlines a structured approach for embarking on a progressive journey to experiment with different LLM usage methods. All the approaches mentioned below start from simplicity and gradually move towards complexity, considering ease-of-use, cost, and resource considerations.
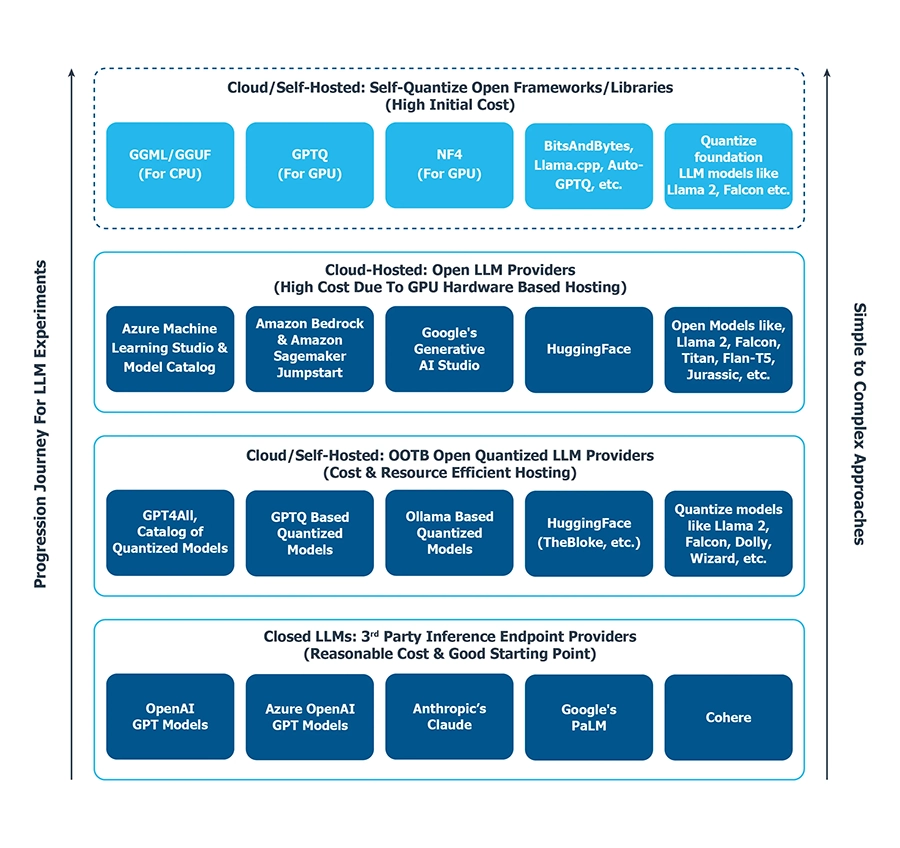
1. Accessing Closed LLMs via External APIs
This is the most straightforward way to harness the power of LLMs. Closed LLMs can easily integrate into applications with minimal effort and optimized costs. It is the simplest method to create quick proofs of concept or even for production to expedite application development.
There are various good-quality closed LLMs available from different providers. Azure OpenAI and OpenAI offer powerful LLMs, such as the GPT series models (GPT-3.5-turbo and GPT-4). Anthropic’s Claude, Google’s PaLM, Cohere, Jurrasic, BloombergGPT, and others represent a handful of closed LLMs that are third-party hosted and can be interacted with via APIs. The number of tokens used in the input and generated as part of the output determines the pricing for most of these models.
These APIs typically have different context window variants, so it’s crucial to consider these when designing a solution for a specific use case. For example, GPT-4 offers two context window variants: 8K and 32K tokens.
This option provides a cost-effective and less risky approach compared to other options. It also offers the flexibility to change the underlying model by simply updating the API implementation.
2. Self-Hosted Quantized Open LLMs
Quantization, in simple terms, involves compressing model weights to reduce the model’s size and memory footprint. Quantization converts a 32/16-bit model into lower precision, such as 8-bit or 4-bit, significantly reducing the memory footprint of the model. An 8-bit model requires four times less memory, making it more affordable. By reducing the model’s size, memory requirements, and computational demands without significantly sacrificing model accuracy, quantized models become more accessible to users who may not have access to high-end GPUs like Nvidia A100.
Quantized models can be loaded and executed on consumer-grade CPUs or GPUs. You can deploy many quantized models available out-of-the-box with an inference endpoint on a regular-grade CPU or GPU for inference.
A few examples include GPT4All, GPTQ, ollama, HuggingFace, and more, which offer quantized models available for direct download and use in inference or for setting up inference endpoints.
This option is cost and resource-efficient, as already quantized models require minimal CPU/GPU and RAM requirements to self-host an inference endpoint. However, achieving optimal inference endpoint performance requires a superior design and better resource planning.
Note: You must evaluate these quantized models for accuracy for the given use cases before any production usage. Also, only certain types of hardware may support these models and quantized techniques, so you should verify the hardware requirements before utilizing these models.
3. Cloud-Hosted Open LLMs
Open LLMs are significant and demand-intensive hardware requirements (CPU/GPU/high RAM). The RAM size required for setting up an inference endpoint varies depending on the number of parameters in LLM models (e.g., 7 billion, 13 billion, 65 billion). The bigger the model, the higher the GPU/RAM requirement.
You can set up these models either on-premises or on-cloud. Most cloud providers, such as Azure, AWS, and GCP, offer infrastructure and libraries for open LLMs, enabling quick setup of an inference endpoint.
Models can be set up on-premises, too, but would require a higher initial investment to procure hardware. We recommend opting for a cloud-based approach for quickly deploying open LLMs without a significant upfront cost, especially considering the dynamic nature of this field and ongoing research to make these models accessible on consumer-grade hardware.
Examples of cloud-hosted open LLM models include Llama2, Falcon, Dolly, Flan-T5, Vicuna, etc.
This option is the most expensive, as setting up an inference endpoint for foundational LLM models with many parameters demands substantial GPU-based hardware and increased RAM. Meeting low-latency service level agreements and high availability requirements would necessitate additional infrastructure, making the solution costly. Therefore, it is crucial to evaluate the costs against the business value.
4. Self-Hosted and Self-Quantized Open LLMs
This option involves using various quantization techniques and libraries to quantize LLM models independently. It focuses on post-training quantization approaches where quantization techniques are applied to pre-trained foundational models to reduce their size, memory, and computing power requirements. During the quantization process, it’s important to note that these models don’t undergo any further training.
You can quantize a model into 8-bit, 5-bit, 4-bit, etc. precision models.
Here are a few techniques to quantize/compress the LLM base foundational models.
Here are a few libraries that can help quantize LLM-based foundational models.
Please note that Hugging Face’s Transformers library integrates Auto-GPTQ and Bitsandbytes. Also, understand that this option is complex and requires in-depth research skills to accomplish quantization with various quantization techniques available. It would be best if you used pre-quantized models unless it’s necessary and you have a deep understanding of different quantization techniques.
Implementing this approach involves a substantial initial investment in skilled engineers, resources, and time. If we experiment with promising outcomes to create well-established libraries, we can significantly reduce the infrastructure costs later.
Conclusion
In this post, we have explored diverse options for a progressive journey in LLM model-based experiments for organizations or projects. All options are arranged from simple to complex approaches and suggest advanced frameworks to make informed decisions for any use case. This post has focused explicitly on trying out-of-the-box models and strategies without fine-tuning.
Originally published on Medium - https://medium.com/@genai_cybage_software/integrating-gen-ai-in-your-product-ecosystem-c6de8d136b03