Modern AI agents are no longer defined by clever prompts. They are defined by how well they manage context and memory over time. This blog explores the critical disciplines of Context Engineering and Memory Engineering, and how Cybage helps organizations implement these capabilities across diverse industry verticals.
The Strategic Shift: From Prompts to Systems
The evolution of AI systems demands a fundamental rethinking of how we architect intelligent agents. While prompt engineering helped us write clearer instructions, it breaks down when AI systems need to:
- Handle multi-step workflows
- Retrieve external knowledge
- Maintain long conversations
- Resume tasks days or weeks later
Context Engineering determines what the model sees right now. Memory Engineering determines what the system remembers across time. Together, they transform LLMs from reactive responders into adaptive, learning systems that deliver enterprise-grade AI with continuity, personalization, governance, and scale.
Why Context Engineering Matters
The core challenge isn't what you ask the model; it's what information the model has available at decision time. Prompt-only systems suffer from:
- Fixed context window limits
- Information loss in long conversations
- No dynamic data injection
- Poor balance between completeness and efficiency
This is where Context Engineering becomes essential.
What Is Context Engineering?
Context Engineering is the discipline of dynamically curating the model's context window so the agent always sees the right information at the right time.
It goes beyond prompts to manage:
- Dynamic information injection from tools, APIs, documents, and memory
- Token efficiency, avoiding context overload
- Retrieval quality, preventing noise and context collapse
- Temporal relevance, ensuring current information drives decisions
If prompt engineering is writing good instructions, context engineering is organizing the entire workspace.
The Context Engineering Lifecycle
Modern agents follow a continuous execution loop:
- Intent Recognition
User input is parsed and context needs are identified. - Knowledge Retrieval
External sources and memory stores are queried. - Context Curation
Information is filtered, ranked, summarized, and token-optimized. - Model Execution
The LLM reasons, generates output, or triggers tools. - Context and Memory Sync
New insights are extracted and stored for future use.
This loop enables coherent behavior across complex, multi-turn workflows.
Core Pillars for Context Engineering
Prompt = Instruction: What you tell the system to do
Context = Workspace: What information is available during execution
Memory = Filing System: What knowledge persists across sessions
An intelligent agent continuously curates its workspace, retrieves past knowledge, acts, learns, and updates memory.
Managing Large Context Windows
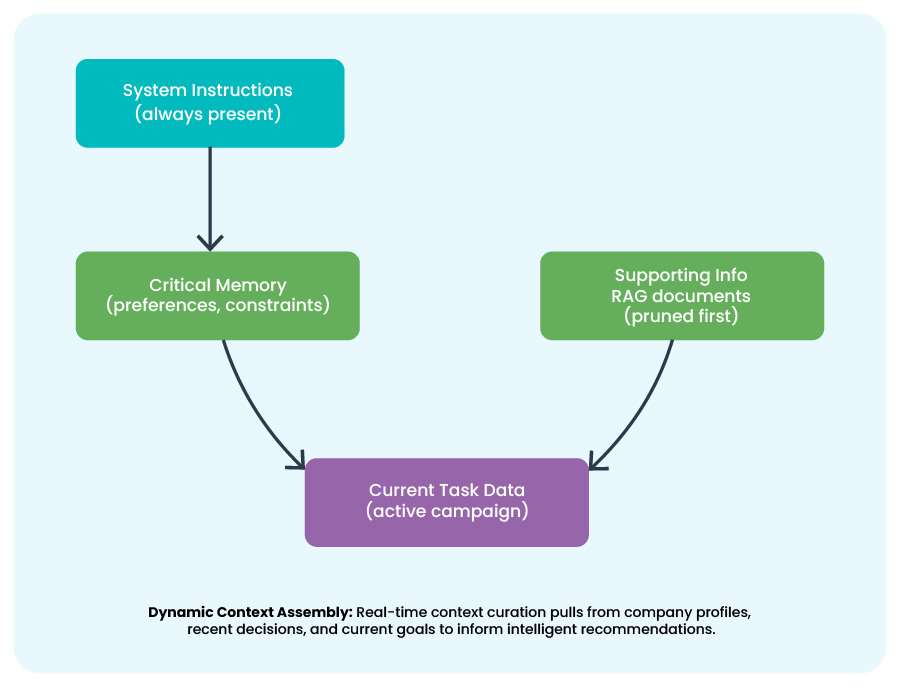
Bigger context windows don't eliminate the need for discipline. Effective strategies include:
- Sliding windows with summarization
- Hierarchical summaries (recent = detailed, old = compressed)
- Selective retrieval using semantic search
- Context layering (system → critical → supporting information)
Real-World Scenario: Enterprise Marketing Strategy Copilot
User: Head of Marketing at a mid-market B2B SaaS company
Goal: Plan, execute, and optimize marketing campaigns over multiple quarters
The agent must: remember past campaigns, learn budget preferences, track outcomes, and resume work after long gaps.
Scenario 1: The Problem with Stateless Systems
In January, the Head of Marketing asks an AI assistant to help plan a Q1 demand-generation campaign. Over several conversations, they finalize:
Target segment: Mid-market B2B SaaS
Budget: ~$60K
Channels: LinkedIn + webinars
In March, the user returns and says:
"Let's plan our next campaign."
The AI responds:
"What industry are you in? What's your budget?"
Insight: The model is intelligent, but the system is not.
To avoid repetition, the user creates a massive prompt:
"You are a marketing expert. The company is B2B SaaS, mid-market, prefers LinkedIn, budget ~60K..."
What goes wrong:
- Prompt grows every session
- Token limits hit
- Old decisions fall out of context
- No learning across sessions
Key message:
Prompt engineering scales instructions, not intelligence. That's where Context Engineering helps.
Context Engineering in Action
Scenario 2: Solving with Context Engineering
When the user asks: "What budget should I allocate for the next campaign?"
The system builds context dynamically, instead of relying on a static prompt.
Example Context Object Injected at Runtime:
json
context = {
"current_goal" : "Plan next marketing campaign",
"company_profile" : {
"industry" : "B2B SaaS",
"segment" : "Mid-market"
},
"recent_decisions" : [
"Previous budget ~60K",
"LinkedIn performed best"
],
"timeframe" : "Q2 planning"
}
Result:
The agent now recommends a budget increase with reasoning, within the same session.
But once the session ends, context disappears. That's where Memory Engineering helps.
Context as an Engineered Object
In production-grade agents, context is no longer treated as raw text sent to a model. Instead, it becomes a structured and governed decision workspace assembled dynamically at runtime, with clear ownership, relevance rules, and lifecycle controls.
Modern context engineering focuses on ensuring the model receives information that is meaningful, prioritized, and explainable — not just more text.
Advanced systems therefore model context using principles such as:
- Typed information — goals, constraints, memories, and supporting evidence
- Ranked importance — prioritizing high-value signals over secondary details
- Time-awareness — favoring recent and valid information over stale context
- Traceability — maintaining clarity on why a piece of context was included
This structured approach allows agents to reason about context quality rather than consuming information blindly.
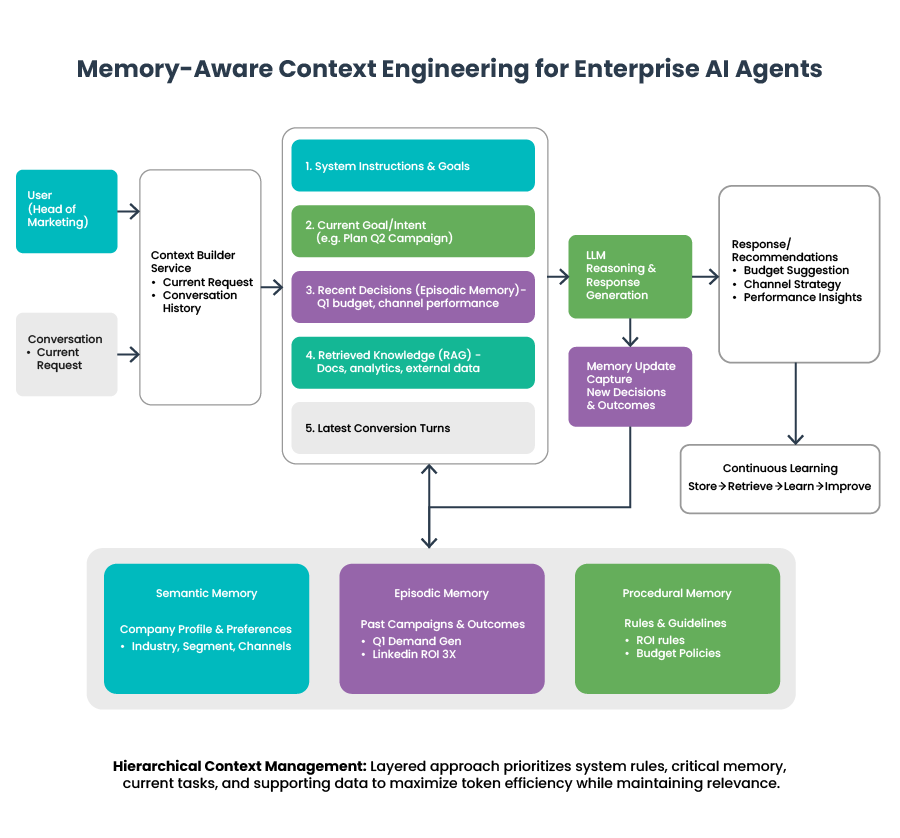
Example: Context Built as a Decision Workspace
When planning the next marketing campaign, the system may dynamically assemble context like this:
Current Goal
Plan Q2 demand-generation campaign.
Business Context
Mid-market B2B SaaS organization focused on performance-driven marketing.
Relevant Memory
Previous campaign achieved strong ROI using LinkedIn webinars with an approximate $60K budget.
Constraints and Guidelines
Recommendations should remain ROI-driven and explain budget changes clearly.
Supporting Evidence
Recent campaign analytics and performance benchmarks.
This structured approach enables agents to reason about context quality, not just consume it blindly.
Memory Engineering: Enabling Continuity Across Time
Scenario 3: The Memory Challenge
In April, the user returns:
"Let's review how our last campaign performed."
Question: Where does the agent retrieve past budget, channel performance, and decision rationale?
Answer: It can't, unless we engineer memory.
Context answers what the model sees now.
Memory answers what the model remembers over time.
Without memory, agents forget everything when a session ends.
Memory Engineering designs how agents:
- Store knowledge
- Retrieve relevant history
- Update beliefs
- Maintain continuity across sessions
It transforms reactive chatbots into adaptive assistants.
Types of Memories Used in Agentic Systems
Short-Term Memory
Conversation history, scratchpads, intermediate reasoning
→ Exists only during active sessions
Long-Term Memory
Preferences, experiences, learned patterns
→ Persists across days, weeks, or months
Context is the workspace.
Memory is the filing system.
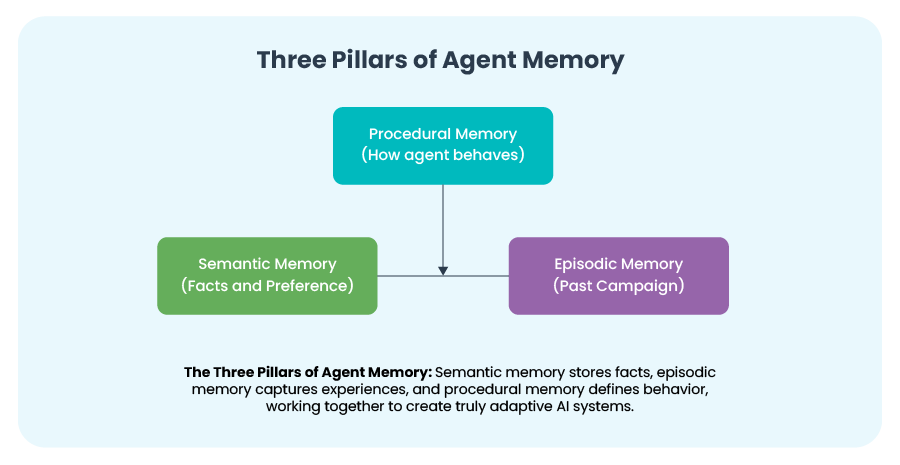
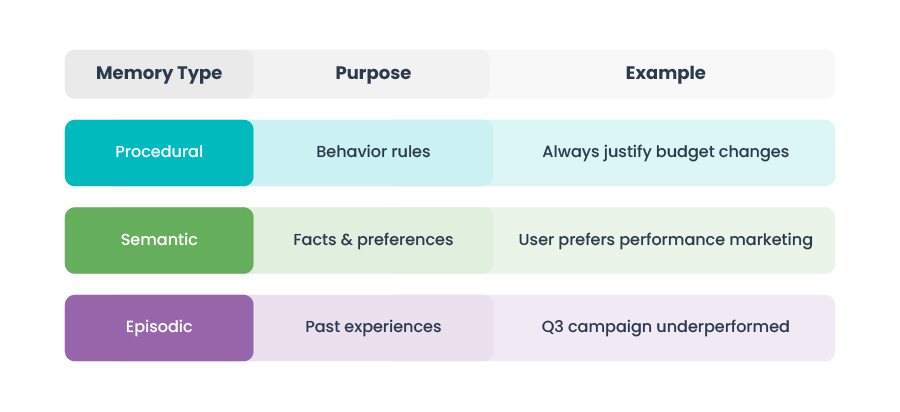
Three Pillars of Agent Memory
Implementation: Memory in Practice
Semantic Memory (Facts):
json
{
"company_type" : "B2B SaaS",
"segment" : "Mid-market",
"preferred_channels" : [
"LinkedIn",
"Webinars"
]
}
Episodic Memory (Experience):
json
{
"campaign" : "Q1 Demand Gen",
"budget" : "60K",
"outcome" : "High MQLs, low CPL",
"timestamp" : "2025-03"
}
Procedural Memory (Behavior):
json
{
"response_style" : "Executive summary first",
"decision_framework" : "ROI-driven recommendations"
}
Writing Memory After Campaign Review
python
memory_store.add({
"type" : "episodic",
"content" : "Q1 campaign used 60K budget; LinkedIn delivered best ROI",
"tags" : [ "campaign", "performance" ]
})
Retrieving Memory for a New Decision
python
relevant_memories = memory_store.search(
query = "budget recommendations for next campaign",
top_k = 3
)
Now the agent answers:
"Based on your Q1 campaign where LinkedIn delivered the highest ROI with a 60K budget, I recommend increasing spend by 15% for Q2."
Stateless vs Stateful Agents
A stateless agent:
- Loses all contextual grounding after each request-response cycle
- Fails at tasks requiring cross-turn reasoning or historical awareness
- Cannot adapt behavior based on user-specific patterns
A stateful agent with well-implemented memory:
- Maintains short-term conversational context across dialogue turns
- Persists long-term user embeddings for personalization
- References episodic events for situational awareness
- Executes procedural sequences without re-deriving them each time
The Five Pillars of Memory Engineering
- Memory Creation and Capture
Extract meaningful knowledge from interactions - Memory Retrieval and Search
Relevance, recency, precision - Memory Summarization
Prevent bloat while preserving value - Memory Synchronization
Keep context and memory aligned - Memory Governance
Privacy, retention, compliance
Production systems use hybrid storage architectures:
- Vector databases for semantic recall
- Graph databases for relationship-rich knowledge
- NoSQL for flexible histories
- In-memory stores for speed
- Relational databases for auditability
Graph-based memory is especially powerful, enabling agents to reason over connected knowledge instead of isolated facts.
Memory-Aware Orchestration with LangGraph and LangMem
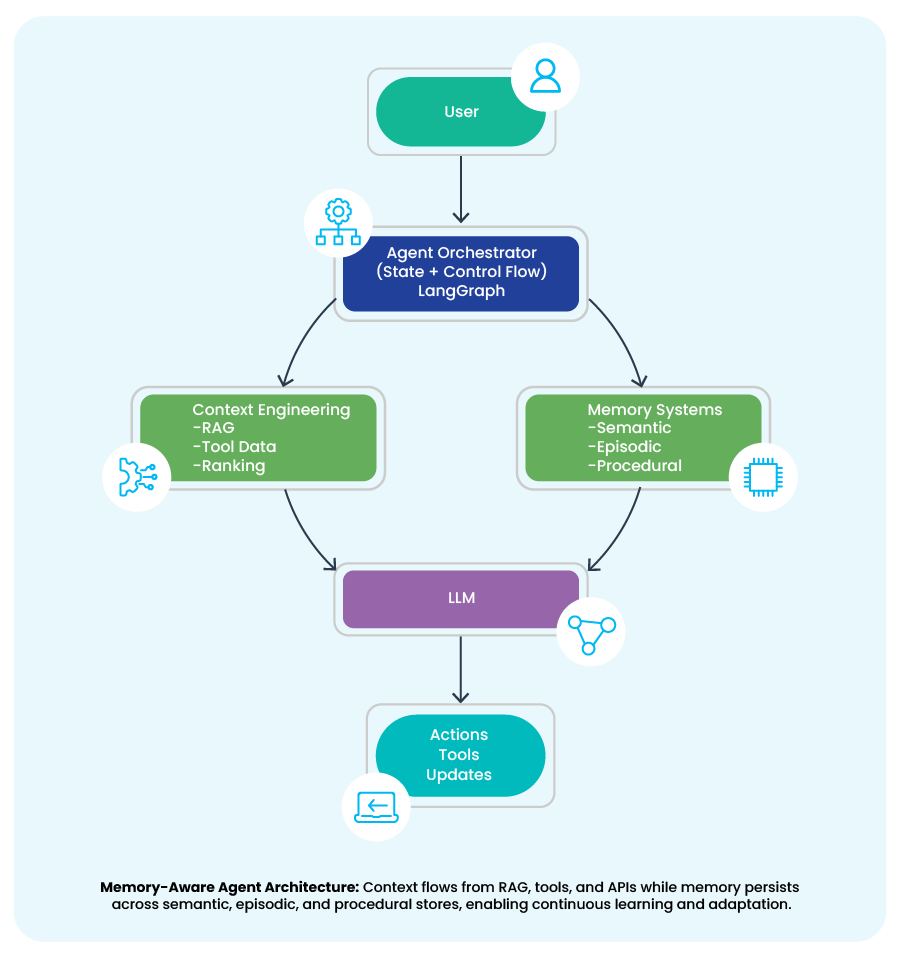
LangGraph acts as the graph controller for context and memory flow in agentic systems. User input enters a stateful graph where each agent node (task processing, retrieval, tool execution, formatting) reads from and writes to a shared memory store.
Context is dynamically assembled from conversation state, vector knowledge, and tool outputs, while memory persists as a serializable state object across graph steps. Conditional routing, checkpointing, and human-in-the-loop controls ensure that execution paths are driven by current context and historical memory, not static prompts.
Outcome: LangGraph converts ad-hoc prompt chains into deterministic, debuggable, memory-centric AI systems that scale to enterprise workflows.
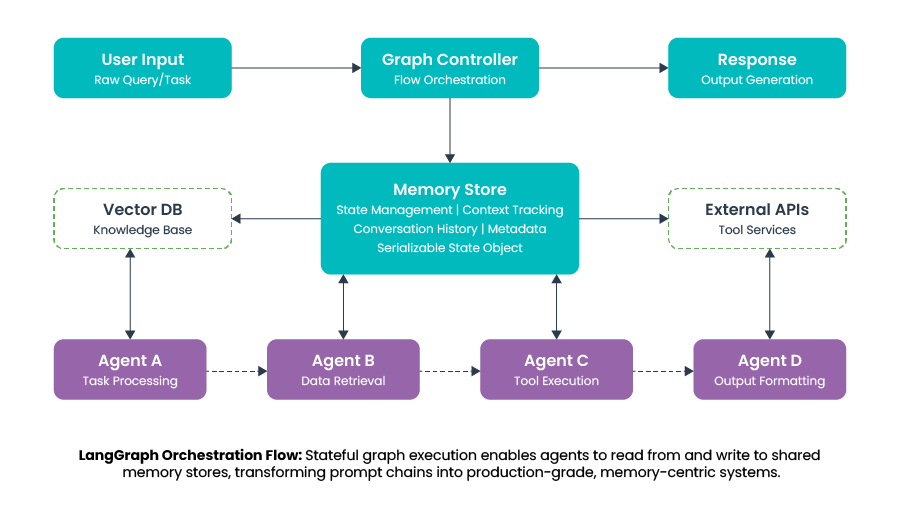
LangMem adds persistent, intelligent memory, automatically extracting, recalling, summarizing, and evolving agent knowledge across sessions.
Together, they turn fragile prompt chains into production-grade, memory-aware agent systems.
Production System Architecture: Memory-Enabled AI Agent
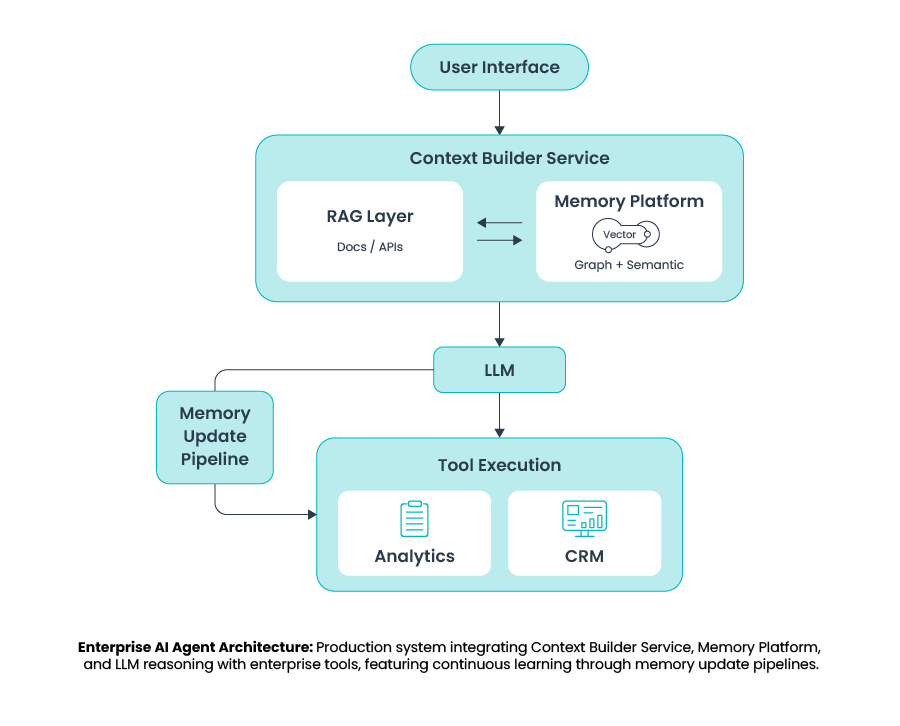
This architecture shows a memory-aware, context-driven AI agent system:
- User input is processed by a Context Builder Service that dynamically assembles context from two sources:
- RAG (documents/APIs for external knowledge)
- Memory Platform (vector + graph memory for persistent user and system knowledge)
- The curated context is sent to the LLM for reasoning, which may invoke enterprise tools
- Outcomes are fed back through a Memory Update Pipeline, allowing the agent to learn and improve across interactions
The Cybage Advantage: Delivering Context and Memory Engineering at Scale
While the technical frameworks exist, successful implementation requires deep expertise across AI architecture, enterprise integration, and industry-specific workflows. Cybage accelerates enterprise AI transformation by combining 25+ years of software delivery experience with cutting-edge AI capabilities.
Why Organizations Choose Cybage
1. Deep Technical and Industry Expertise
Cybage brings production-grade engineering practices for scalable, secure AI systems combined with vertical-specific domain knowledge across healthcare, retail, financial services, and manufacturing. Our teams understand both the technology stack (LLM architectures, RAG systems, vector databases) and the business context that drives ROI.
2. Hybrid Context Management
We implement sophisticated context strategies that balance real-time data integration from enterprise systems (ERP, CRM, analytics), semantic search across documents, temporal relevance scoring, and token optimization to maximize context window efficiency.
3. Production Infrastructure with Built-in Governance
Cybage delivers scalable vector and graph database implementations, multi-tenant memory isolation for SaaS applications, real-time synchronization between context and memory stores, role-based access control, automated PII detection and redaction, and audit trails that meet regulatory requirements.
Industry-Specific Applications: How Cybage Enables Context and Memory Engineering
Healthcare: Patient-Centric Clinical Assistants
Use Case:
AI-powered clinical decision support that remembers patient history, treatment preferences, and clinical guidelines.
Cybage Implementation:
- Memory Architecture: Semantic (patient demographics, conditions, allergies), Episodic (treatment history, outcomes), Procedural (clinical pathways, guidelines)
- Context Integration: Real-time EHR, lab results, imaging data
- Compliance: HIPAA-compliant with patient data isolation and complete audit trails
Business Impact:
40% reduction in diagnostic time, improved treatment adherence, reduced medical errors
Financial Services: Personalized Wealth Management Advisors
Use Case:
AI agents that understand client goals, risk tolerance, and market conditions for tailored investment advice.
Cybage Implementation:
- Memory Architecture: Semantic (client profiles, preferences), Episodic (portfolio performance, transactions), Procedural (investment strategies, compliance rules)
- Context Integration: Real-time market data, regulatory updates, portfolio analytics
- Compliance: SEC/FINRA-compliant audit trails with explainable AI
Business Impact:
3x increase in client engagement, 50% reduction in advisor time on routine queries, enhanced compliance
Retail: Omnichannel Customer Experience Agents
Use Case:
AI assistants that maintain shopping context across web, mobile, and in-store interactions.
Cybage Implementation:
- Memory Architecture: Semantic (product preferences, brand affinities), Episodic (purchase history, browsing), Procedural (return policies, promotional rules)
- Context Integration: Real-time inventory, pricing, customer location, cart state
- Privacy: GDPR/CCPA-compliant with user consent management
Business Impact:
25% increase in conversion rates, 60% reduction in cart abandonment, improved customer satisfaction
Cybage's Value Proposition
Organizations that partner with Cybage gain:
- Speed to Production: Implementations in months, not years
- Expertise Across the Stack: AI architecture, enterprise integration, and vertical-specific requirements
- Ongoing Optimization: Continuous improvement and support for measurable business outcomes
The shift from stateless prompt systems to stateful, memory-aware agents represents the next frontier in enterprise AI. Organizations that master context and memory engineering will build AI systems that don't just respond, but truly understand, learn, and adapt.